
Free AI tools usually fail in small, annoying ways before they fail.
The page loads, but the button doesn’t respond. The tool generates half an answer, then freezes. The same prompt works at 9 a.m., but times out after lunch. You refresh, paste the same input again, and hope the system remembers what it was doing.
Most users blame the AI model. Sometimes they blame their browser. But the problem is often less glamorous: the backend wasn’t built for the kind of traffic the tool is now getting.
That matters because free AI tools live or die on trust. If someone uses a sentence rewriter, essay helper, image generator, or email writer once and it breaks, they don’t think, “Interesting infrastructure challenge.” They think, “This tool doesn’t work.”
Free tools create traffic spikes that normal apps don’t always see
A paid B2B product can often predict usage. Teams log in during work hours. Seats are limited. Activity follows a pattern.
Free AI tools behave differently. A TikTok video, Reddit thread, classroom assignment, newsletter mention, or Google ranking jump can send thousands of people to the same tool without warning. One hour, a generator is quietly handling normal traffic. Next, everyone wants a poem, slogan, essay outline, or product description at the same time.
That’s where backend planning starts to show.
A simple writing tool may look lightweight on the surface: text box, button, output. Behind that button, though, the system may need to check user limits, route the prompt, call a model, wait for a response, store the result, handle retries, and return everything cleanly to the page. When demand jumps, each step becomes a possible bottleneck.
The companies that avoid those failures usually think about scaling before the homepage gets busy. Cloud teams have treated automation as part of normal tech operations because traffic, compute needs, and costs move too quickly for manual fixes to keep up. For an AI tool, that can mean automatically adding capacity when prompts pile up, moving workloads away from overloaded services, or shutting down unused resources before the bill gets ugly.
The user never sees any of that. They only see whether the output arrives.
That’s the point. Good backend work feels boring from the outside. The page loads. The tool responds. The result appears before the user starts wondering if it broke. The better the infrastructure, the less anyone talks about it.
The real problem is not popularity. It’s a messy demand
A free AI tool does not need to be famous to strain its backend. It only needs uneven demand.
Think about a student using a ChatGPT essay writer the night before a deadline. Now multiply that by thousands of students in the same week. Their prompts may be longer than expected. They may ask for multiple drafts. They may paste messy instructions, restart generations, or open the tool in several tabs because nothing appears fast enough.
That kind of behavior is normal. It is also expensive to serve badly.
The mistake is designing for the average user instead of the busiest real moment. Average traffic makes dashboards look calm. Peak traffic exposes every weak assumption. If the backend can handle 1,000 short prompts per hour but struggles with 300 long, repeated, model-heavy requests in five minutes, the average number was never the useful one.
Good execution starts with sharper questions:
- What happens when 500 people click generate within the same minute?
- What happens when the AI provider slows down?
- What happens when users submit very long prompts?
- What happens when one tool goes viral but the rest of the site is quiet?
- What happens when free users retry because they don’t see progress?
The last question is especially important. A slow tool creates more traffic by making people impatient. Users click again. They refresh. They submit the same request twice. A backend that was merely busy can become overloaded because the interface gives no clear feedback.
A better tool tells users what is happening. It can show a loading state, limit duplicate submissions, queue requests, or return partial progress where appropriate. These are not fancy features. They are small decisions that stop human behavior from turning into infrastructure chaos.
Even something as basic as an AI email writer has this problem once enough people use it for sales outreach, job applications, customer replies, and cold emails at the same time. The tool may feel simple, but the use cases are not equal. A three-line thank-you note and a personalized outreach sequence do not require the same processing effort.
Speed is part of the product, not a technical bonus
People judge AI tools quickly. They don’t wait like they used to.
A blog editor might tolerate a slow export from professional software because the job is complex and the account is paid. A casual user trying a free title generator is less patient. If the tool hesitates, they open another tab. If the next tool answers faster, loyalty is gone before it starts.
Speed is not only about raw server power. It is about how the whole request moves.
Some delays come from the model. Some come from poorly written application logic. Some come from database calls that should have been cached. Some come from sending every request through the same narrow path, even when certain jobs could be handled separately.
Cloud providers describe scaling as the ability to rapidly provision and release computing resources, which is the basic idea behind the NIST definition of cloud computing. In plain English: the system should be able to get more room when it needs it and stop paying for that room when it doesn’t.
For AI tools, that idea becomes practical in very specific ways. A short slogan generator may need fast, lightweight handling. An image generator may need heavier computing and more careful queueing. A long-form editor may need autosave, session memory, and slower background processing. Treating all of those requests the same is how tools become sluggish.
Good teams separate workloads. They keep quick tasks quick. They prevent heavy tasks from blocking simple ones. They cache common outputs where it makes sense. They set timeouts that fail clearly instead of trapping the user in a spinning wheel.
They also watch the right signals.
A backend dashboard that says “server is up” is not enough. The better question is whether users are getting usable responses within a reasonable time. Error rate matters. Queue depth matters. Model latency matters. Cost per generation matters. Retry volume matters because it often reveals frustration before complaints arrive.
Google’s Cloud Run documentation, for example, describes autoscaling around traffic and instance demand, including metrics-based and on-demand scaling for services. That kind of thinking matters because traffic is not just a number; it is a moving pattern of requests that need different handling depending on timing, size, and urgency.
A tool can be technically online and still feel broken. Users do not care that the server returned something eventually. They care whether the tool helped them finish the task before they lost momentum.
The biggest blind spot is treating “free” as low stakes
Free tools are often treated like side doors into a product. Build them fast. Rank them. Let users try them. Move serious users toward the paid plan.
That can work, but only if the free experience is stable enough to create confidence.
A broken free tool does not feel like a limited preview. It feels like a warning. If the free generator fails during a small task, why would someone trust the same company with bigger work? If a free AI writing generator times out on a simple paragraph, the user may assume the paid experience has the same cracks.
This is where many teams misread the funnel. Free users are not all low-value users. Some are students today and founders later. Some are marketers testing five tools before choosing one for a team. Some are creators who will recommend whatever saves them time. Their first experience carries more weight than the price tag suggests.
There is also a cost problem hiding behind the user experience problem. AI tools can become expensive fast when the backend is careless. Long prompts, repeated generations, abandoned sessions, spam traffic, and poorly controlled retries can burn through compute without creating happy users.
A healthier setup has boundaries. Free tools need rate limits, but not rude ones. They need abuse prevention, but not so much friction that normal users leave. They need queues, but not silent queues. They need graceful failure messages that tell someone what to do next instead of pretending nothing happened.
The best free AI tools make constraints feel reasonable. They might limit the number of generations, shorten very large inputs, ask users to sign in after a threshold, or prioritize simple requests during high demand. What matters is that the user understands the tradeoff.
“Try again later” is not helpful.
“Your request is unusually long; shorten it for a faster result” is better.
“High demand right now, your result is queued” is better than a frozen button.
People can tolerate limits when the tool is honest. What they dislike is uncertainty.
Wrap-up takeaway
Free AI tools do not break down only because too many people show up. They break because the backend was designed for a cleaner, calmer version of user behavior than the one that actually happens. Real users paste long prompts, retry too fast, arrive in waves, and judge the tool before they understand what is happening behind the page. The strongest free tools are built with that messiness in mind: clear feedback, smart scaling, workload separation, fair limits, and enough monitoring to spot trouble early. A useful next move today is simple: pick one free AI tool you rely on and notice where it slows down, confuses you, or makes you retry—the weak point you feel as a user is often the backend problem builders need to fix first.
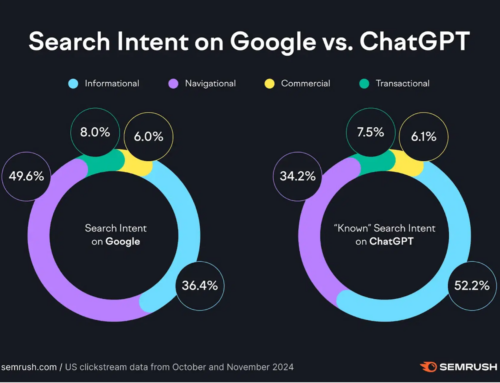

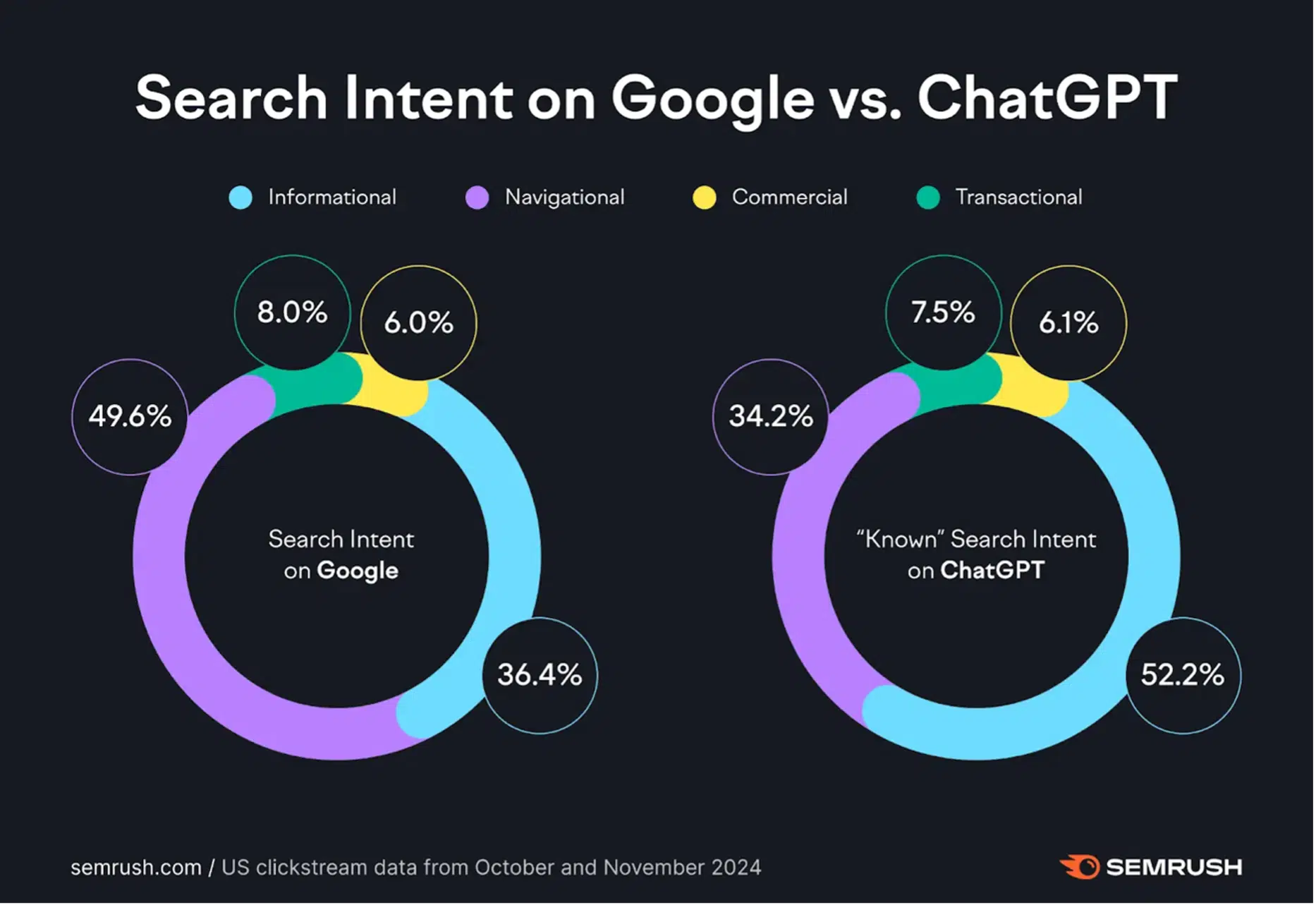{kind=link}
{kind=link}
{kind=link}